众邦银行隐私计算助力金融行业反欺诈风控
2023-02-13 12:57:55 |来源:壹点网

文 / 众邦银行风险管理部兼大数据风控部总经理 田羽
随着信息通信技术的发展,各行各业信息系统采集、处理和积累的数据量越来越多,全球大数据储量呈爆炸式增长。2020年,中共中央国务院公开发布的《关于构建更加完善的要素市场化配置体制机制的意见》首次将数据作为一种新的生产要素类型,表示数据资源的开放共享、交换流通成为重要趋势,也表明数据要素的高效配置是推动数字经济发展的关键一环。数字化转型已成为金融业提高服务质量和竞争力的共同选择,为客户带来更加高效、优质的金融服务。
在数字化技术应用的同时,给反欺诈带来了严峻挑战。在巨大经济利益的驱动下,通过木马、钓鱼链接、电信诈骗等各种手段骗取客户资金的案件层出不穷。2021年以来,日渐猖獗的欺诈个人及团伙对金融机构造成了严重损失,如何实现精准反欺诈,保护储户、银行双方资金安全,是当下金融机构迫切需要解决的问题。
金融行业反欺诈难点
金融行业主要为企业及个人提供金融服务,自身所拥有的数据也大多属于金融业务数据,存在数据维度单一、数据量不足等问题。外部数据来源通常为征信报告、公开数据以及从其他外部机构获得原始数据,由于各行各业对于数据安全以及隐私保护标准日渐提高,直接获取外部机构原始数据不再可行。在反欺诈场景中,单个金融机构主要使用自身数据,特别是新户客户获取资料有限,难以覆盖所有金融市场主体和识别所有的金融欺诈行为。金融机构迫切需要结合自身的金融数据及外部数据联合提升反欺诈效果,解决金融机构内部数据无法出库、外部数据无法引入问题,打破因数据保护和商业壁垒产生的“数据孤岛”,实现数据价值安全流转,是解决金融行业欺诈问题的重要途径之一。
数据流通新模式——隐私计算
隐私计算(Privacy-Preserving Computation)是指在保证数据提供方不泄露原始数据的前提下,对数据进行分析计算的一系列信息技术,在保障数据流通与融合的同时实现数据“可用不可见”,是一套融合了密码学、安全硬件、数据科学、人工智能、计算机工厂等众多领域的跨学科技术体系,主要包含了联邦学习和多方安全计算等的技术方案。
联邦学习(联合机器学习):联邦学习是一种分布式机器学习技术,通过联合两个或多个参与方使用安全的算法协议进行联合机器学习,可以在各方数据不出本地的情况下进行联合多方数据建模,同时可根据已有模型进行推理与预测。在训练或计算过程中,各参与方只交换密文形式的中间参数或中间结果,不交换数据,保证各方数据不暴露。联邦学习也可结合同态加密、不经意传输、秘密分享等加密技术进一步提高计算安全性。
联邦学习由横向联邦学习与纵向联邦学习组成。横向联邦学习常用解决于多个参与方拥有相同数据字段,通过联合各方不同用户数据解决单一机构数据量不足问题。纵向联邦学习常用于多个参与方拥有不同数据字段且存在大量重合用户场景,通过联合各方相同用户不同维度的数据解决单一机构数据维度不足问题。
多方安全计算:由姚期智院士在1982年提出,指参与者在不泄露各自隐私数据情况下,利用隐私数据参与加密计算,共同完成计算任务。相较于联邦学习,多方安全计算无需进行模型训练,主要通过不经意传输、同态加密、秘密分享、混淆电路、零知识证明等加密分享技术,参与方通过对原始数据进行加密、转换后再提供给其他参与方,任意参与方都无法接触到其他参与方的原始数据,保证各方数据安全。多方安全计算技术常用于隐私集合求交、隐私信息检索及隐私统计分析,以及规则分析等场景。
众邦银行基于隐私计算
在反欺诈场景的应用
1.众邦银行—运营商联合建模。相较于传统反欺诈模型,众邦银行已推进落地与运营商合作建设基于隐私计算的反欺诈模型。在该业务场景中,众邦银行与运营商达成深度合作,旨在拥有充分用户授权的情况下,基于隐私计算纵向联邦学习的技术底层,运用运营商合规数据赋能金融行业反欺诈场景。双方本地数据标签备份,众邦银行准备欺诈样本标签,金融交易属性特征,运营商则提供通话特征、行为特征、在网特征等,通过联邦学习在双方数据均不出库的前提下,利用数据建模和大数据分析挖掘技术,高效、快捷地构建用户反欺诈体系,有效提升用户筛选功能,提升贷款质量,防止恶意欺诈。
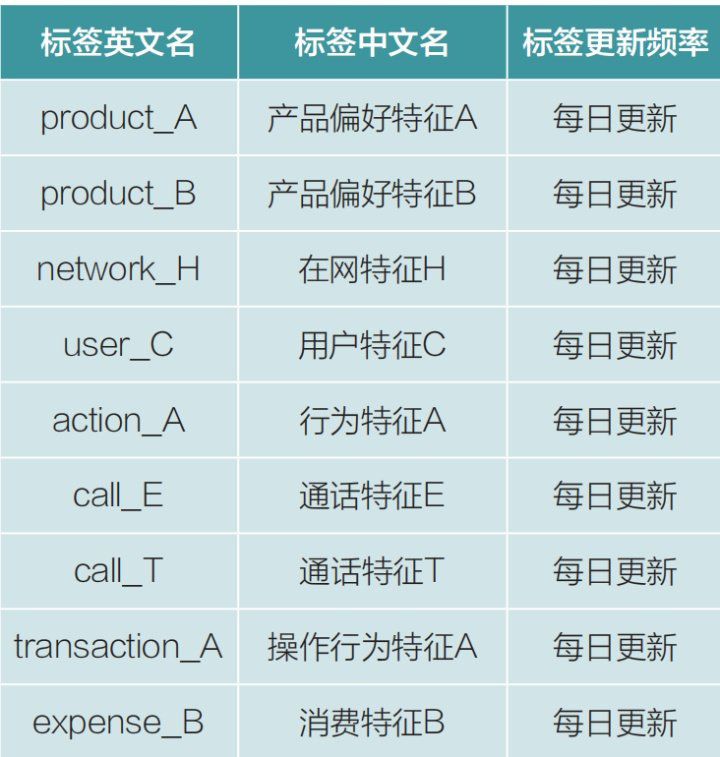
在本次训练模型中,主要运用以下几个维度的数据进行计算,分别是:在网特征、通信消费、用户偏好与用户行为。通过联邦学习丰富了反欺诈手段、提高了反欺诈综合能力,更高效发现欺诈风险,欺诈概率较之前下降约10%。衍生字段特征如表所示。
表 衍生字段特征
2.构建跨行业跨机构的反欺诈生态。在传统数据分析场景中,受制于数据隐私的保护,不同机构的数据无法汇集。众邦银行通过隐私计算技术可帮助组建包含政府、监管机构、银行、运营商等跨行业跨机构的反欺诈联盟(如图所示)。
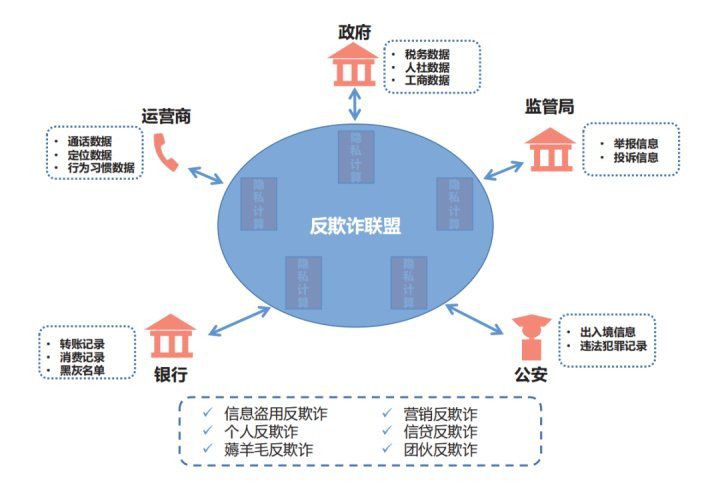
图 跨行业跨机构的反欺诈联盟
众邦银行利用已搭建的隐私计算平台,与合作金融机构、外部数据源建立可通讯的隐私计算节点。不同金融机构间结合自身已有的欺诈、黑灰名单样本和行内金融属性的相关特征通过横向联邦学习扩充各自的反欺诈样本,同时银行将自身金融属性的相关特征与外部数据源通过纵向联邦学习构建多维度的反欺诈融合模型,数据在传输过程中通过隐私求交技术进行跨机构间的样本安全对齐,确保各参与方除了交集样本外无法获知或反推其他参与方的非交集样本,模型最后结果与反欺诈系统进行对接应用。基于联邦学习算法构建的反欺诈模型对比仅基于行内数据构建的模型KS提升了20%以上,通过拒绝2%的客户逾期下降4%。通过建立基于隐私计算的跨行业的反欺诈联盟,解决了多方数据协作的合规性和安全性问题,挖掘数据潜能,精准识别欺诈类用户,提升通过率的同时,降低了逾期率,并避免了数据在多方间的跨企业流动的风险,实现数据价值的安全共享。
行业前景
随着互联网金融的兴起,各类欺诈行为逐渐渗透到数字金融的各个环节。反欺诈的分析及建模需要海量多维化数据,本地训练模型成本较高,且各机构对数据的隐私性和安全性要求极为严格,反欺诈推动缓慢。据《银行4.0》一书中提到,目前全球每年只有约3%的欺诈案例被识破,通过隐私计算技术可帮助构建跨行业反欺诈生态、联合多个不同行业如运营商、银行、保险机构、公安等机构数据为反欺诈提供海量数据支撑以提升金融反欺诈能力。
社会影响
众邦银行作为首家互联网交易银行,始终秉承“专注产业生态,帮扶小微企业、助力大众创业”的使命,以交易场景为依托,以线上业务为引领,以供应链金融为主体,以大数据风控为支撑。大数据风控作为业务场景的重要基石应不断跟随政策、法规时代的发展而被探索。众邦银行利用运营商数据基于隐私计算技术助力银行反欺诈风控体系的落地,在数据生产要素需要安全流转的今天,无疑推动银行风控体系巨大进步,不仅解决了银行内部数据与外部数据的“数据孤岛”问题,更是能利用多方合法合规的外部数据源参与模型的制作和对风控效率的提升。众邦银行基于隐私计算技术搭建的数据开放生态网络,旨在引入更多的合法合规数据源,是带领深度依赖大数据的金融风控体系迈向了探索数据合规、数据流转和数据高效治理的道路,同时也是为数据作为生产要素,加快数据要素市场化,推动数字化高质量安全发展,构建以政策法规为依归、技术创新为特征、绿色发展为目标、数字要素为核心、安全可信为基础的数据要素市场化配置新体系提供了坚实场景。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
关键词:
标签阅读
-
众邦银行隐私计算助力金融行业反欺诈风控
2023-02-13 -
房贷可贷到80岁?南宁:真的!还没还完 人就离世了怎么办?...
2023-02-13 -
世界热文:女儿18岁送什么礼物有意义
2023-02-13 -
焦点简讯:回收黄金首饰多少钱一克(2023年2月13日)
2023-02-13 -
全球观察:今日中国黄金基础金价(2023年2月13日)
2023-02-13 -
【天天报资讯】金至尊今天黄金价格多少一克(2023年2月13日)
2023-02-13 -
当前头条:今天周大生黄金首饰价格行情(2023年2月13日)
2023-02-13 -
亚一黄金价格今天多少一克(2023年2月13日)
2023-02-13 -
当前速看:传统小贷进退两难,跨省网络小贷“去肥增瘦”
2023-02-13 -
80后富二代接棒百神药业闯A,推广费占销售费用八成以上被监管...
2023-02-13 -
环球微动态丨光能杯 · 跨年分享会 | 索比光伏网总编曹宇...
2023-02-13 -
当前聚焦:回南天自救指南 小天鹅超薄全嵌洗烘套装解锁衣物...
2023-02-13 -
世界播报:我国四天内发生12起地震,正常吗?专家回应
2023-02-13 -
【独家】不少网友反映微信头像褪色,官方回应:尽快恢复
2023-02-13 -
环球焦点!入境游“暖了”!山东迎来三年来首个入境旅游团
2023-02-13 -
热讯:一券商宣布:2月16日起 关闭内地股民港、美股账户!
2023-02-13 -
渤海银行大额存单到期了啥时到账? 银行大额存单转让利息如...
2023-02-13 -
从东方女性肤质特点出发,高效抗老选植物医生高山红茶系列
2023-02-13 -
保险可以异地退保吗? 异地退保注意事项
2023-02-13 -
【天天聚看点】赛特新材:股东拟减持不超过2.66%的股份
2023-02-13





